Il s'agit du quatrième épisode de la série de messages sur les composants malveillants, où nous présentons le Xygéni approche pour gérer cette menace, dans le cadre de notre couverture pour Open Source Security.
Nous avons constaté que l'excès de confiance dans les composants open source de source incertaine est exploité par des malfaiteurs de toutes sortes pour produire un comportement inattendu qui peut être exécuté sur les machines des développeurs, CI/CD systèmes, ou intégrés aux logiciels de l'organisation victime, afin qu'ils soient transmis à ses clients. Nous avons décortiqué épisode 2 les attaques utilisant des registres publics pour diffuser des logiciels malveillants et ce que nous avons appris après avoir observé comment les acteurs malveillants opèrent, et dans le précédent épisode 3 les contrôles qui fonctionnent (et ceux qui échouent) contre cette menace ont été examinés.
Il est maintenant temps d’examiner notre approche du problème. Dans cet épisode, nous présentons quelle est la stratégie que nous suivons chez Xygeni pour notre Alerte précoce contre les logiciels malveillants (MEW). Comment ce système à plusieurs étapes fonctionne en temps réel lorsqu'une nouvelle version du package est publiée, comment les preuves sont capturées à partir de différentes sources, comment le tri est effectué, quels critères de classification suivons-nous et pourquoi une analyse manuelle est encore nécessaire pour confirmer la nature d'un package candidat malveillant. Nous expliquerons également comment nous aidons NPM, GitHub, PyPI et d'autres infrastructures clés des écosystèmes open source à réduire le temps de séjour des logiciels malveillants.
Le pipeline
Xygeni Malware Early Warning (MEW) traite en continu des composants, soit des archives de packages pour les bibliothèques et les frameworks pour les écosystèmes de programmation pris en charge comme JavaScript/Node ou Python, des images de conteneurs Docker/OCI, soit des extensions et des plugins pour des outils comme les IDE ou CI/CD systèmes. Ces composants sont publiés dans des registres publics avec différents niveaux de contrôle des utilisateurs.
Voici une vue schématique du fonctionnement du système :
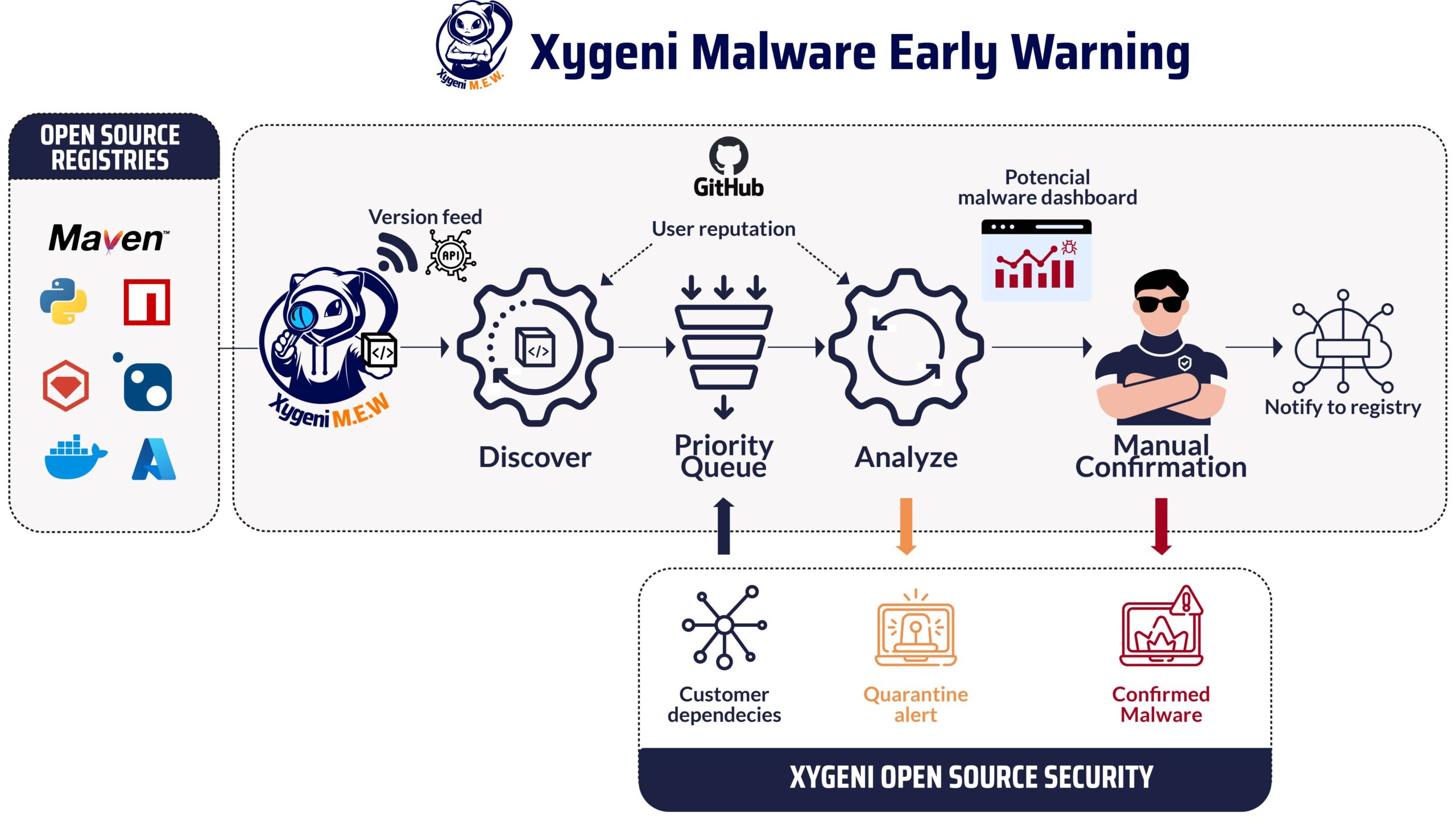
Le découvreur le processus reçoit le flux des événements de publication. Un événement de publication est la création d'une nouvelle version d'un composant nouveau ou existant. Comme les registres populaires ne proposent pas de mécanisme pub-sub pour les consommateurs intéressés, cela se fait souvent en interrogeant le registre sur les événements récents. Un excellent projet de l'OSSF, flux de paquets, Soutien des registres populaires comme PyPI ou Maven Central, et fournissent une interface unifiée basée sur les flux. Dans MEW, nous avons ajouté des implémentations spécifiques qui réduisent le temps d'attente, par exemple avec une réplique de la base de données CouchDB utilisée par NPM qui est synchronisée avec la base de données du registre public.
Chez Xygeni, nous avons un inventaire[1] de tous les composants (directement ou indirectement) utilisés par les logiciels de nos clients. Les coordonnées des composants des clients sont transmises régulièrement à MEW pour prioriser les analyses : les composants utilisés par nos clients sont traités plus tôt. La priorité est également basée sur la réputation de l'éditeur et le caractère critique du composant, de sorte que les composants provenant d'éditeurs de faible réputation sont également prioritaires.
Le analyseurs puis consommez les composants en attente dans la file d’attente prioritaire. Lorsqu'une version d'un composant est sélectionnée pour analyse, son archive tar est téléchargée à partir du registre. Notez que le composant binaire packagé est analysé : la plupart des composants open source proviennent généralement d'un référentiel open source, souvent sur github.com, qui est utilisé à des fins de contexte uniquement, et le malware est toujours recherché dans l'archive tar du composant car les acteurs malveillants systématiquement mentir sur les sources qu'ils prétendent avoir utilisées pour créer l'archive tar des composants qu'ils publient.
Du point de vue de l'utilisateur
Je vous entends penser : comment puis-je bénéficier d'une connaissance précoce d'une version d'un package malveillant ? Dans l'épisode « Anatomie des packages malveillants : quelles sont les tendances ? » nous avons vu que le temps d'arrêt total est de l'ordre de quelques jours, tandis que la première notification de MEW aux clients utilisant le composant concerné est de l'ordre de quelques minutes. Avec un simple garde-corps[2] vous pouvez bloquer la build (il existe deux niveaux d'alerte, un entièrement automatisé lorsque le moteur conclut à la présence d'un malware potentiel et une notification ultérieure lorsque notre équipe de sécurité confirme par inspection manuelle la présence d'un malware). Il est généralement trop tard pour attendre que le registre confirme le malware et le supprime du registre en raison de la longue fenêtre d'exposition.
L'organisation peut utiliser un garde-fou qui vérifie s'il existe un composant potentiellement malveillant (dans l'un des deux niveaux d'alerte) ou, via l'API, savoir rapidement si l'une des dépendances directes ou indirectes d'un projet logiciel utilise un composant malveillant.
Comment fonctionne MEW : détails internes
Le noyau : moteur de détection des logiciels malveillants
L'analyseur utilise différents détecteurs pour capturer les preuves d'actes répréhensibles. Les détecteurs combinent analyse statique, analyse de capacités et analyse contextuelle[3], comme décrit dans le post précédent de cette série.
Chez Xygeni, nous disposons d'une équipe d'ingénieurs avec une longue expérience en analyse statique, et c'est la principale différence avec les autres solutions anti-malware. Notez que pour certains écosystèmes, l'archive tar packagée contient soit du code source (par exemple, du code JavaScript ou TypeScript pour les packages NPM, des sources Python pour les packages PyPI), soit du code compilé suffisamment proche du code source pour une analyse statique (par exemple, du bytecode dans les fichiers JAR pour Maven). . Pour d'autres, comme les images de conteneurs, les exécutables binaires sont courants, c'est pourquoi l'inférence de capacités est la technique utilisée, ainsi que la détection conventionnelle des logiciels malveillants basée sur les règles YARA et les signatures des logiciels malveillants.
Veuillez noter que les technologies simples comme les expressions régulières ou les signatures ne sont pas appropriées pour détecter les comportements malveillants. Imaginez détecter un dropper ou un téléchargeur : du code ou un binaire se trouve dans le package ou est téléchargé à partir d'un domaine externe, sans rapport avec le composant (il peut s'agir d'un domaine externe). grande liste de domaines achetés par l'acteur malveillant[4] domaine légitime pour échapper à la détection). Ce code est ensuite exécuté à l'aide de l'une des fonctions prévues à cet effet. Le code peut être transformé pour masquer l'URL de téléchargement ou la fonction utilisée pour exécuter le code téléchargé. Une analyse complète du flux de données est nécessaire pour le détecter, en utilisant toute la machinerie de l'analyse statique, ou une exécution en bac à sable (si les conditions d'exécution d'un comportement malveillant sont réellement remplies) pourrait le détecter dans le cas général.
Les acteurs menaçants suivent les mêmes techniques et des détecteurs ont été conçus et mis en œuvre pour eux. Il existe également certaines étapes de prétraitement, par exemple pour supprimer l'obscurcissement, souvent nécessaires pour découvrir le comportement caché.
Ajout de contexte
Certains détecteurs utilisent des informations contextuelles. Par exemple, une inadéquation entre la version dans le registre des composants et la balise/version dans le référentiel GitHub associé constitue une preuve solide qu'un acteur malveillant a peut-être obtenu des informations d'identification de publication pour le registre mais pas pour le référentiel GitHub. Attaques comme celle affectant le fournisseur de portefeuille cryptographique Ledger pourrait être facilement détecté par cette inadéquation.
A score de malveillance (MS) est calculé à partir des résultats des détecteurs exécutés, en fonction de la force des preuves capturées. Toutes les conclusions ne sont pas identiques et l’ordre d’exécution est pertinent.
Réputation des utilisateurs et des composants
Tous les développeurs open source ne sont pas égaux !
Un développeur réputé peut voir son compte NPM piraté (cela se produit même avec des personnes sensibilisées à la sécurité) et des logiciels malveillants publiés à l'aide de ce compte. De toute évidence, la réputation devrait chuter brusquement et ne retrouver sa gloire passée que lorsque le compte piraté est récupéré et que le développeur corrige les conditions qui ont conduit au rachat du compte. La réputation est difficile à gagner mais peut être perdue en un instant.
Chez MEW, nous avons mis en place un système complet de gestion de la réputation pour récompenser les comportements positifs et pénaliser les activités suspectes. Ce système commence avec les nouveaux utilisateurs dans une position neutre et ajuste leur réputation en fonction de leurs activités en cours.
La réputation d'un utilisateur s'améliore grâce à des actions positives telles que le maintien de comptes de réseaux sociaux actifs, l'activation de l'authentification multifacteur, la contribution régulière à des projets et la signature. commits avec des clés vérifiables. À l'inverse, la réputation se détériore en raison d'actions hostiles telles que la publication de logiciels malveillants, l'utilisation d'adresses e-mail jetables, le refus de signer commits, ou présentant des modèles inhabituels dans les contributions.
L'objectif principal de notre système est de garantir un environnement sûr et digne de confiance. Il y parvient en ajustant dynamiquement la réputation des utilisateurs en fonction de divers facteurs, tout en respectant les préoccupations en matière de confidentialité et les limites des différents registres.
Un score de réputation interne est calculé pour l'utilisateur (en rejoignant le registre et le compte github lorsque cela est possible), ainsi que le score de malveillance utilisé lors de la classification du composant analysé, et pour mieux qualifier qui est sous la publication du composant.
Des preuves d'un comportement malveillant ont été trouvées. Et alors? Le processus de révision manuelle
Le classificateur actuel classe la version du composant analysée dans l'une des catégories « malveillant confirmé », « probablement malveillant », « à haut risque », « à faible risque » ou « non malveillant » en fonction de seuils sur les scores condensant les résultats et la réputation de l'utilisateur/du composant. Une classification en catégories « à haut risque » ou « probablement malveillant » déclenche l'examen manuel et la première notification. La catégorie « malveillant confirmé » est définie après un examen manuel ou lorsque les preuves correspondent aux mêmes preuves pour une version précédente qui a été confirmée comme malveillante.
Lorsqu’il existe suffisamment de preuves d’un comportement malveillant potentiel, une première alerte (alerte de quarantaine) est émise aux organisations concernées. Comme mentionné précédemment, cela peut bloquer l'installation ou la construction de logiciels dépendant du composant mis en quarantaine.
Cela crée un problème au sein du MEW interne dashboard afin que les analystes de sécurité puissent démarrer le processus de révision manuelle du composant. L'équipe dispose d'outils spécialisés (bac à sable, désobfuscateurs, distribution pour la recherche de logiciels malveillants, outils de reporting des logiciels malveillants) pour évaluer rapidement la nature de la version du composant étudiée. La plupart des malwares (« les anchois » ou composants malveillants peu sophistiqués) sont passés en revue
Le résultat de l'examen conclut soit sécuritaire, le moteur d'analyse automatique a donc trouvé un faux positif qui est utilisé comme retour au classificateur d'apprentissage automatique pour apprendre le modèle ; ou confirmé malveillant, de sorte que le composant est divulgué de manière responsable comme malveillant dans le registre public, à la suite du processus de signalement. Une deuxième notification est envoyée aux organisations concernées, qui peuvent à leur tour lever la quarantaine du composant, ou le bloquer définitivement de leur processus de mise à niveau de version ou du pare-feu de composant utilisé dans leur registre interne.
Ce paramètre nous permet d'analyser quotidiennement des dizaines de milliers de nouvelles versions et d'identifier les dizaines probablement malveillantes, que nous examinons ensuite manuellement. Rappelez-vous de l’épisode précédent qu’un sur dix mille est le taux de composants malveillants que nous voyons actuellement dans la nature.
Déclaration au Registre
Nous avons constaté que la plupart des registres publics, l'un des piliers de l'infrastructure open source, fournissent des mécanismes assez limités pour signaler les problèmes de sécurité, et les composants malveillants en particulier. Nous nous efforçons d'améliorer l'organisation sous-jacente du processus de reporting. En règle générale, nous recevons tout au plus un e-mail de retour de l'équipe de sécurité du registre confirmant que le composant a été supprimé du registre.
Parfois, le registre fait l'objet d'abus, enfreignant ses conditions d'utilisation, mais sans provoquer de comportement malveillant dans le logiciel fourni. Ceci est également signalé au registre, mais il n'est pas notifié aux organismes visant à limiter le bruit.

Travail futur
De nombreuses améliorations sont actuellement sur la feuille de route. Avant tout, un portail public pour la santé des composants du système d'exploitation, notamment en ce qui concerne les preuves de malveillance potentielle trouvées, est actuellement en cours de développement. Il s'agit d'une modeste contribution à la communauté open source. Restez à l'écoute.
Un autre développement en cours est une amélioration classificateur d'apprentissage automatiqueMEW tirera des leçons des classifications passées. Le vecteur de résultats des détecteurs du moteur, ainsi que le score de malveillance et le score de réputation dérivés du composant et de l'éditeur (« les preuves trouvées »), sont utilisés comme données d'entrée par un système d'apprentissage automatique qui met à jour le modèle de classification. La variable de sortie indique simplement si le registre a confirmé la malveillance du composant. Ce nom de code, « l'Oracle », contribuera à une meilleure compréhension.cise qualificatif, conçu pour être solide (rappel élevé, c'est-à-dire ne pas manquer de composants malveillants) mais avec moins de faux positifs (ne pas signaler les composants sûrs comme malveillants).
A score de criticité sera ajouté pour des critères de priorisation, en plus de l'appartenance à l'ensemble des dépendances des clients, et de la mauvaise réputation de l'éditeur. Il est clair que les projets ayant plus d’influence et d’importance devraient être examinés plus tôt pour analyse. Nous ne réinventerons pas la roue ici et suivrons les Score de criticité du projet Open Source.
Le soutien à des écosystèmes supplémentaires est en cours de développement. Des technologies et des outils répandus comme les plugins PHP ou Jenkins sont dans la feuille de route.
Nous étudions également si le processus d’examen manuel pourrait être facilité par l’IA afin de rationaliser l’analyse des quelques composants malveillants plus sophistiqués.
Dans le prochain et dernier volet de cette série, «Exploiter l'Open Source : à quoi s'attendre des méchants», nous nous concentrerons sur les dernières méthodes adoptées par les adversaires pour rendre les attaques plus furtives, plus difficiles à détecter, plus ciblées sur des secteurs spécifiques et plus rentables. Les attaques de ransomware seront-elles lancées à l’aide de ce véhicule ? Comment les méchants exploitent-ils les outils d’IA pour diffuser des logiciels malveillants plus sophistiqués ? Les projets les plus populaires sont-ils menacés ? L’objectif est de donner aux lecteurs une idée de cette course aux armements et de ce à quoi s’attendre à court terme (second semestre 2024) et à moyen terme (2025).
Nous terminerons par quelques réflexions sur les petits pas que la communauté pourrait faire sans trop changer l'ouverture du monde open source. Par exemple, un mécanisme plus efficace pour signaler les logiciels malveillants aux registres publics et partager les preuves de composants potentiellement malveillants avec les registres et la communauté constituerait un petit pas dans la bonne direction vers l’objectif consistant à fermer les portes aux acteurs malveillants.
Les logiciels malveillants présents dans les composants open source ne devraient pas perturber les énormes avantages que la communauté open source a apporté à notre société.
- [1] Notre scanner détecte les composants open source référencés par les projets logiciels analysés, de sorte que le graphique de dépendances complet et à jour est connu, au moins pour les projets analysés régulièrement. Xygeni OSS expose une API que les clients peuvent également utiliser lors de la mise sur liste blanche d'un composant d'intérêt, y compris des informations sur les vulnérabilités et les preuves malveillantes.
- [2] Un garde-corps peut interrompre la construction si une condition correspondant à des problèmes de sécurité est détectée. Les découvertes de sécurité telles qu’une vulnérabilité critique et accessible ou l’utilisation d’un composant mis en quarantaine pourraient être considérées comme suffisamment graves pour interrompre la version du logiciel concerné.
- [3]Nos analystes de sécurité exécutent le composant ou ses scripts d'installation dans un environnement sandbox si nécessaire. Cependant, MEW n'effectue pas d'analyse dynamique, principalement parce que le comportement malveillant n'est pas toujours mis en œuvre dans le cadre d'attaques ciblées et en raison de la logique d'évasion utilisée par les acteurs malveillants pour échapper à l'analyse dynamique.
- [4] Cette technique a reçu un nom, Registered Domain Generation Algorithms ou RDGA, et de nouveaux acteurs de menace comme ce qu'on appelle Lapin revolver a investi jusqu'à 1 million de dollars dans 500 XNUMX domaines, démontrant à quel point l'industrie de la cybercriminalité est rentable.