Ihre SAST Der Scanner hat in diesem Sprint 847 Probleme gemeldet. Ihr SCA Das Tool hat 312 weitere Einträge hinzugefügt. Ihr Geheimnisscanner hat 43 potenzielle Sicherheitslücken in vier Repositories gefunden. Und irgendwo unter diesen über 1,200 Funden befindet sich eine kritische Schwachstelle, die aktuell aktiv ausgenutzt wird. Das ist AppSec-Warnungsmüdigkeit. Und es handelt sich nicht um ein Erkennungsproblem.
Die meisten Teams haben kein Problem mit der Erkennung von Warnmeldungen, sondern mit deren Priorisierung. Ohne Kontext erscheinen alle Warnmeldungen gleich dringlich, sodass keine als dringlich genug empfunden wird, um sofort zu reagieren.
Genau in dieser Lücke zwischen Erkennung und Priorisierung können echte Bedrohungen durchschlüpfen.
Dieser Leitfaden erläutert, warum Alarmmüdigkeit auftritt, welche Kosten damit verbunden sind und welche konkreten Techniken sich anwenden lassen, um sie zu reduzieren, ohne die Sicherheitsabdeckung zu beeinträchtigen.
Was ist AppSec-Alarmmüdigkeit (und warum verschlimmert sie sich)?
AppSec-Alarmmüdigkeit beschreibt den Zustand, in dem Sicherheits- und Entwicklungsteams von der Flut an Sicherheitswarnungen so überfordert sind, dass ihre Reaktionsfähigkeit stark beeinträchtigt wird. Wenn alles als „kritisch“ eingestuft wird, erscheint nichts mehr dringlich. Echte Bedrohungen gehen im Informationsrauschen unter.
Das Ausmaß des Problems ist beträchtlich. Laut Bericht „Stand der Anwendungssicherheit 2025“ von Cypress Data Defense62 % der Sicherheitsverantwortlichen haben wissentlich anfällige Anwendungen ausgeliefert, um Fristen einzuhalten – nicht etwa, weil sie die Schwachstellen nicht kannten, sondern weil sie nicht schnell genug reagieren konnten. Marktübersicht KI-SOC bis 2025 Das durchschnittliche Alarmaufkommen liegt bei mittelständischen Unternehmen bei 960 pro Tag und steigt auf über 3,000. enterprises über 20,000 Mitarbeiter.
AppSec verschärft das Problem insbesondere aufgrund dreier struktureller Faktoren:
Werkzeugvielfalt. Sicherheitsteams, die mit mehreren Inselwerkzeugen arbeiten, verfügen über keinen gemeinsamen Kontext. Ein „kritischer“ Eintrag in Ihrem SCA Werkzeug und ein „kritisches“ in Ihrem IaC Scanner landen ohne Zusammenhang im selben Backlog. Laut Devos Bericht „Evolution zu einem alarmlosen SOC“ aus dem Jahr 202583 % der SOC-Experten fühlen sich von der Vielzahl der Alarme, Fehlalarmen und dem fehlenden Kontext der Alarme überfordert, und 84 % der Unternehmen berichten, dass Analysten unwissentlich dieselben Vorfälle mehrmals pro Monat untersuchen.
CVSS-Priorisierung an erster Stelle. CVSS-Werte messen den Schweregrad einer Sicherheitslücke, nicht die Wahrscheinlichkeit ihrer Ausnutzung. Eine CVE mit einem Wert von 9.8 (kritisch) hat möglicherweise eine nahezu nullprozentige Wahrscheinlichkeit, in den nächsten 30 Tagen Ziel eines Angriffs zu werden. Die Behebung einer solchen Sicherheitslücke vor der aktiven Ausnutzung einer CVE mit einem Wert von 6.5 ist reine Entwicklungszeitverschwendung und erzeugt ein trügerisches Gefühl des Fortschritts.
Kein Laufzeitkontext. Eine Schwachstelle in einer Abhängigkeit stellt ein ganz anderes Risiko dar, je nachdem, ob diese Abhängigkeit öffentlich zugänglich ist oder in einem internen Entwicklungstool ausgeführt wird, ob die anfällige Funktion tatsächlich aufgerufen oder zwar importiert, aber nicht verwendet wird oder ob bereits kompensierende Schutzmechanismen in der Umgebung vorhanden sind. Tools, die diesen Kontext nicht berücksichtigen, erzeugen unabhängig davon dieselbe „kritische“ Warnung.
Das Ergebnis: Bis zu 53 % der Sicherheitswarnungen sind Fehlalarme.Laut dem Devo SOC Performance Report 2024 lernen die Entwicklerteams, Störfaktoren zu ignorieren, und echte Bedrohungen gelangen so unentdeckt durch.
Die wahren Kosten der Aufmerksamkeitsmüdigkeit
Alarmmüdigkeit ist keine bloße Unannehmlichkeit. Sie ist ein direkter Weg zu Sicherheitslücken.
Wenn Analysten überlastet sind, entwickeln sie Bewältigungsstrategien: Sie priorisieren Aufgaben anhand der Schwere der Probleme anstatt des tatsächlichen Risikos, verschieben Ergebnisse auf unbestimmte Zeit in den nächsten Sprint, schließen Warnmeldungen als „wird nicht behoben“, um den Backlog abzubauen, oder schauen sich die Warteschlange einfach nur noch an. Derselbe Devo-Bericht bestätigt, dass 84 % der Analysten in Unternehmen unbewusst doppelte Untersuchungsarbeit leisten – eine direkte Folge fragmentierter Tools ohne Korrelationsebene.
Die Folgewirkungen:
- Die Sicherheitsschulden häufen sich. Jede nicht erkannte Sicherheitslücke stellt eine Schwachstelle dar, die so lange offen bleibt, wie Angreifer aktiv danach suchen.
- Die Entwickler misstrauen den Werkzeugen.Wenn Sicherheitstools ständig Fehlalarme auslösen, hören Entwickler auf, die Ergebnisse als handlungsrelevant zu betrachten. „Sicherheitswarnungen, die ständig Alarm schlagen“ werden zu einem tief verwurzelten Problem, das sich nur schwer beheben lässt.
- Die durchschnittliche Zeit bis zur Behebung der Mängel verlängert sich. IBMs 2025 Kosten eines Datenverletzungsberichts Die weltweiten Durchschnittskosten einer Datenschutzverletzung belaufen sich laut dieser Studie auf 4.4 Millionen US-Dollar, was einem Rückgang von 9 % gegenüber dem Vorjahr entspricht. Dieser Rückgang wird insbesondere auf die schnellere Erkennung und Eindämmung durch KI zurückgeführt. Teams, die durch die Flut an Warnmeldungen ausgebremst werden, verzichten genau auf diesen Vorteil.
- Team-Burnout. Das ISC2025-Studie zur Cybersicherheits-Belegschaft 2Eine Studie, die auf der Grundlage von 16,029 Cybersicherheitsexperten weltweit durchgeführt wurde, ergab, dass 48 % sich erschöpft fühlen, weil sie versuchen, über Bedrohungen und neue Technologien auf dem Laufenden zu bleiben, und 47 % berichten, dass sie sich von der Arbeitsbelastung überfordert fühlen.
Was ändert sich, wenn man Kontext hinzufügt?
Die meisten AppSec-Programme scheitern an derselben Stelle: zwischen Erkennung und Priorisierung. Scanner erkennen alles. Niemand sagt einem, was zuerst behoben werden soll.
Genau hier setzt Xygeni mit seinem Design an, und das ist der Unterschied zwischen einem Team, das in Benachrichtigungen ertrinkt, und einem Team, das mit einer Warteschlange arbeitet, in der jede Entdeckung eine Reaktion wert ist.
| Ohne Kontext | Mit Xygeni | |
|---|---|---|
| Alarmlautstärke | Tausende pro Woche | Reduziert auf das, was umsetzbar ist |
| Priorisierung | CVSS-Schweregrad | EPSS + Erreichbarkeit + Geschäftsauswirkungen |
| Triage | Handbuch, pro Werkzeug | Automatisiert, einheitlich über alle Tools hinweg |
| Fehlalarm | Bis zu 52 % der Ergebnisse | Sie werden gefiltert, bevor sie die Warteschlange erreichen. |
| Ergebnis | Lärmschutzingenieure ignorieren | Signaltechniker handeln auf |
Die AppSec-Alarmmüdigkeit PipelineWo Teams scheitern
Die meisten Teams scheitern an derselben Stelle. Nicht bei der Erkennung – ihre Tools erkennen genug. Sondern in der Lücke zwischen Erkennung und Deaktivierung.ciseine Möglichkeit für einen Entwickler, darauf zu reagieren.
Erkennen → Korrelieren → Priorisieren → Beheben → Überwachen
Alle Phasen links von „Priorisieren“ lassen sich gut mit bestehenden Tools abdecken. In jeder Phase rechts davon werden Erkenntnisse entweder zu Lösungen oder zu Backlog-Aufgaben. Der Engpass liegt stets in der Mitte: Korrelation und Priorisierung ohne Kontext führen lediglich zu einer Umordnung von Daten.
Die fünf nachfolgenden Techniken decken jede Phase davon ab. pipeline direkt.
Fünf Techniken zur Reduzierung der AppSec-Alarmmüdigkeit
1. Ersetzen Sie die CVSS-basierte Priorisierung durch EPSS + Erreichbarkeit.
CVSS gibt an, wie schwerwiegend eine Sicherheitslücke theoretisch ist. Es sagt jedoch nichts darüber aus, ob sie tatsächlich ausgenutzt wird oder ob Ihre Anwendung überhaupt gefährdet ist.
EPSS (Exploit-Vorhersage-Bewertungssystem)Die von FIRST bereitgestellte Datenbank liefert für jede CVE eine tägliche Wahrscheinlichkeitsbewertung. Wie wahrscheinlich ist es, dass diese Schwachstelle in den nächsten 30 Tagen aktiv ausgenutzt wird? Die Daten sind über eine API öffentlich zugänglich und werden täglich auf Basis aktueller Bedrohungsinformationen aktualisiert.
Die Auswirkungen auf das Alarmaufkommen sind erheblich. Laut FIRSTs eigene ModelldatenEine CVSS-7+-basierte Behebungsstrategie erfordert den Aufwand, 57.4 % aller CVEs zu bearbeiten, um 82 % der ausgenutzten Schwachstellen zu erfassen. Eine EPSS-basierte Strategie (Schwellenwert 0.1) erreicht eine Abdeckung von 63 % mit nur 2.7 % des Aufwands, da sie sich auf die CVEs konzentriert, die Angreifer tatsächlich anvisieren.
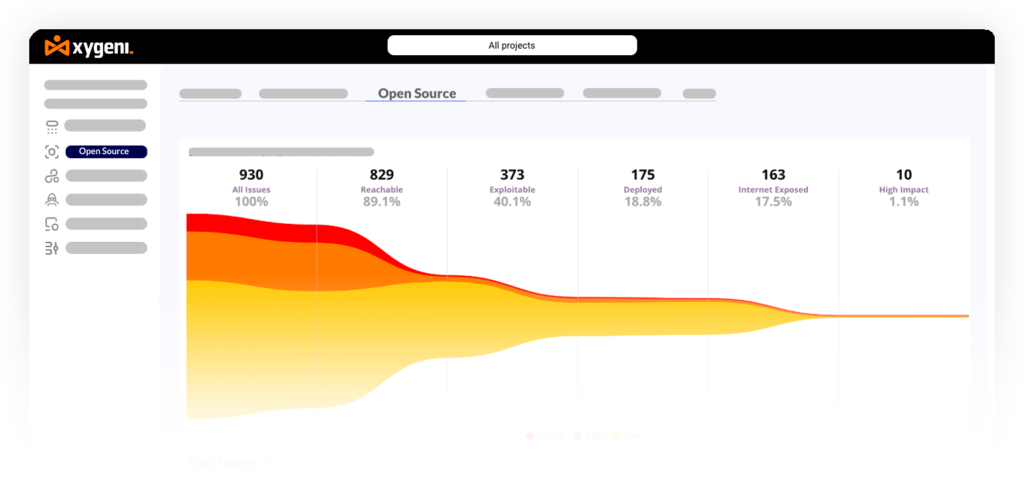
Die Erreichbarkeitsanalyse verstärkt den Effekt noch. Indem analysiert wird, ob die anfällige Funktion in einer Abhängigkeit tatsächlich im Ausführungspfad Ihres Codes aufgerufen wird, kann allein die Erreichbarkeitsfilterung die Reduzierung verringern. SCA Die Ergebnisse um bis zu 80 % verbessern, ohne ein einziges reales Risiko auszulassen.
Die Kombination aus EPSS und Erreichbarkeit bedeutet, dass Ihre Warteschlange die 1-2% der Ergebnisse anzeigt, die tatsächlich sofortiges Handeln erfordern, und nicht die theoretischen 57%.
Xygeni SCA kombiniert die Erreichbarkeitsanalyse auf Funktionsebene mit der Live-EPSS-Bewertung, um Ergebnisse, die in Ihrer Codebasis nicht erreichbar sind oder eine nahezu null Wahrscheinlichkeit der Ausnutzung aufweisen, automatisch herabzustufen. OSS-Priorisierungstrichter Wenden Sie einen progressiven Filter an – Schweregrad der Schwachstelle, Ausnutzbarkeit, Erreichbarkeit und geschäftliche Auswirkungen –, sodass die Warteschlange, die Ihr Team sieht, nur Ergebnisse enthält, die eine manuelle Überprüfung wert sind.cisIon. So funktioniert es →
2. Zusammenführung der Ergebnisse verschiedener Tools zu einer einheitlichen Risikoübersicht
Fragmentierte Tools sind eine der Hauptursachen für die AppSec-Alarmmüdigkeit. Wenn SAST Die Ergebnisse leben in einem dashboard, SCA in einem anderen, IaC Bei Fehlkonfigurationen in einem dritten System gibt es keine Möglichkeit, diese zu korrelieren, kein gemeinsames Schweregradmodell und kein einheitliches Verständnis davon, wie hoch Ihr tatsächliches Risiko ist.
Application Security Posture Management (ASPM) Dies wird dadurch erreicht, dass es als Korrelations- und Priorisierungsschicht über alle Ihre Sicherheitstools hinweg fungiert. ASPM verarbeitet Ergebnisse Ihrer SAST, SCA, Geheimnisscanner, IaC Tools und DAST entfernen dann Duplikate von Befunden, die mehrere Tools über dasselbe zugrunde liegende Problem gemeldet haben, korrelieren Befunde über verschiedene Tools hinweg, um zusammengesetzte Risiken zu identifizieren (eine anfällige Abhängigkeit plus ein offengelegtes Geheimnis im selben Dienst), und wenden einen einheitlichen Geschäftskontext an, welcher Dienst internetseitig ist, welcher sensible Daten verarbeitet, was sich in der Produktion und was in der Testumgebung befindet.
Kontextuelle Priorisierung durch ASPM Reduziert unnötige Störungen um bis zu 90 % und hinterlässt Teams anstelle einer Liste eine priorisierte, umsetzbare Warteschlange.
Xygeni ASPM Xygeni integriert auch Ergebnisse von Drittanbieter-Tools. Wenn Sie bereits Ergebnisse von OWASP ZAP, Acunetix, TruffleHog oder Trivy haben, normalisiert und korreliert Xygeni diese in derselben Risikoansicht zusammen mit den eigenen Scan-Ergebnissen. Sie müssen Ihre bestehende Toolchain nicht ersetzen, um eine einheitliche Übersicht zu erhalten – Sie profitieren vom ersten Tag an von den Korrelationsvorteilen. Die vollständige Liste finden Sie hier. Die unterstützten externen Scanner sind hier dokumentiert..
3. Jede Erkenntnis in einen geschäftlichen Kontext einordnen.
Eine kritische Schwachstelle in einer internen Testumgebung und eine kritische Schwachstelle in einem internetbasierten Zahlungsdienst stellen nicht dasselbe Risiko dar. CVSS kann diesen Unterschied nicht erkennen. Ihre Priorisierungs-Engine muss ihn jedoch erkennen.
Geschäftskontextdimensionen, die die Priorisierung jedes Ergebnisses beeinflussen sollten:
- InternetpräsenzIst der betroffene Dienst über das öffentliche Internet erreichbar? Eine Sicherheitslücke, die mit dem Internet in Verbindung steht, hat ein wesentlich größeres Gefahrenpotenzial.
- DatensensibilitätVerarbeitet dieser Dienst personenbezogene Daten, Finanzdaten oder Zugangsdaten? Eine höhere Datensensibilität erhöht die Kosten eines Datenlecks.
- Produktion vs. Nicht-ProduktionSchwachstellen in Produktionssystemen erfordern schnellere SLAs zur Behebung als solche in Entwicklungs- oder Staging-Systemen.
- Kritikalität von VermögenswertenHandelt es sich um einen zentralen Zahlungsdienst oder ein peripheres internes Tool? Der geschäftliche Nutzen bestimmt die Dringlichkeit.
- Kompensierende KontrollenVerringern bestehende Kontrollmechanismen (WAF-Regeln, Netzwerksegmentierung, Zugriffsbeschränkungen) bereits die Ausnutzbarkeit dieser Erkenntnis in der Praxis?
Wenn diese Dimensionen in Ihr Priorisierungsmodell integriert werden, bedeutet „kritisch“ nicht mehr „Dieser Scanner hat ihm eine 9.8 gegeben“, sondern „Dies ist ausnutzbar, erreichbar, mit dem Internet verbunden, im Produktivbetrieb und verarbeitet Kundendaten.“
4. Feedback frühzeitig einholen: Entwicklern die Ergebnisse zum richtigen Zeitpunkt mitteilen
Ein erheblicher Teil der AppSec-Warnmüdigkeit wird durch Kontextwechsel verursacht. Ein Entwickler, der vor drei Wochen Code veröffentlicht hat und nun eine Sicherheitswarnung in einem Ticket erhält, hat den Bezug zu diesem Code verloren. Die Triage dauert länger, die Rate falsch positiver Ergebnisse steigt und die Behebungen sind von geringerer Qualität.
Durch die Integration von Sicherheitsfeedback in die IDE und den PR-Review wird das Problem direkt an der Quelle behoben. Entwickler sehen die Ergebnisse, während der Code noch im Arbeitsgedächtnis ist. Die Rate falsch positiver Ergebnisse sinkt, da Entwickler sofort beurteilen können, ob das markierte Muster tatsächlich ein Problem in ihrem Code darstellt. Die Qualität der Korrekturen verbessert sich, da der Entwickler den Kontext versteht. Die durchschnittliche Zeit bis zur Behebung verkürzt sich, da keine Übergabe an eine separate Sicherheitswarteschlange erfolgt.
Die praktische Umsetzung: IDE-Plugins, die sichtbar machen SAST Die Ergebnisse werden direkt im Code erfasst, während dieser geschrieben wird; PR-Prüfungen stellen sicher, dass bei neuen kritischen Erkenntnissen ein Zusammenführungsprozess ausgelöst wird; pipeline Richtlinien, die den Einsatz von Geheimnissen oder anfälligen Abhängigkeiten verhindern, bevor diese in die Produktionsumgebung gelangen.
Xygeni DevAI Sicherheitslücken werden direkt in der Entwickler-IDE angezeigt, und KI-generierte Lösungsvorschläge werden anhand der Richtlinien Ihres Unternehmens validiert, sodass Entwickler Probleme beheben können, bevor sie sich negativ auswirken. pipelinenicht, nachdem sie in Produktion gegangen sind. → Mehr erfahren
5. Automatisierte Triage für Befunde mit niedrigem Risiko
Nicht jeder Befund erfordert eine manuelle Überprüfung. Eine Schwachstelle in einer Testabhängigkeit, die nie in der Produktionsumgebung eingesetzt wird, ein Geheimnis in einem Repository, das vor sechs Monaten rotiert wurde, eine Fehlkonfiguration in einer Entwicklungsumgebung ohne externen Zugriff – solche Befunde beanspruchen zwar Zeit für die Triage, führen aber nicht zu einer nennenswerten Risikominderung.
Definieren Sie klare Auto-Triage-Regeln: Automatische Unterdrückung von Befunden in Test-/Entwicklungsumgebungen unterhalb eines konfigurierbaren Schweregradschwellenwerts, automatisches Schließen von Geheimnissen, die bereits widerrufen oder rotiert wurden, Herabstufung (nicht Ignorieren) von Befunden in Abhängigkeiten, bei denen die Erreichbarkeitsanalyse bestätigt, dass der anfällige Codepfad nicht aufgerufen wird, und Unterdrückung bekannter falsch positiver Ergebnisse mit dokumentierter Begründung.
Die wichtigste Disziplin: Automatische Triage-Regeln müssen nachvollziehbar sein und regelmäßig überprüft werden. „Wir haben es unterdrückt“ ist nur dann akzeptabel, wenn Sie nachweisen können, was unterdrückt wurde, warum und wann die Unterdrückung stattgefunden hat.cision wurde zuletzt überprüft. Pauschale Unterdrückung, um die Warteschlange zu leeren, führt dazu, dass echte Sicherheitslücken übersehen werden.
Messung der AppSec-Alarmmüdigkeit: Drei Kennzahlen, die es wert sind, verfolgt zu werden
Was man nicht misst, kann man nicht reduzieren. Diese drei Kennzahlen liefern Ihnen eine Ausgangsbasis und ermöglichen es Ihnen, Verbesserungen zu verfolgen:
Signal-zu-Rausch-VerhältnisWie hoch ist der Anteil an Warnmeldungen, die zu einer Behebung führen, im Vergleich zu solchen, die als Fehlalarm, nicht behebbar oder Duplikat geschlossen werden? Ein gut funktionierendes AppSec-Programm strebt einen Anteil von mindestens 40 % an. Liegt dieser Wert unter 20 %, liefert Ihr Tool mehr Fehlalarme als relevante Informationen.
Mittlere Zeit bis zur Triage (MTTT)Wie lange dauert es von der Erstellung eines Befundes bis zur Entscheidung eines Mitarbeiters?cisEin langes MTTT deutet oft entweder auf ein zu hohes Alarmvolumen oder auf unzureichenden Kontext in der Alarmmeldung selbst hin.
Mittlere Zeit bis zur Behebung (MTTR) für kritische ErkenntnisseInsbesondere bei Feststellungen, die Ihr Team als prioritär einstuft, wie lange dauert es von der Entdeckung bis zur Behebung? Diese Kennzahl korreliert direkt mit dem Risiko eines Sicherheitsvorfalls.
Wie Xygeni die AppSec-Alarmmüdigkeit umfassend angeht
Genau hier scheitern die meisten AppSec-Programme. Und genau darauf konzentriert sich Xygeni bei seinem Design.
AppSec-Warnungsmüdigkeit ist ein Plattformproblem. Insellösungen erzeugen Informationsrauschen, da ihnen der Kontext fehlt. Kontext erfordert die Korrelation von Tools, Laufzeitsignalen, Daten zu Geschäftsauswirkungen und Informationen zur Ausnutzbarkeit – und das wiederum erfordert eine einheitliche Plattform.
| Aufgabenstellung: | Xygeni-Fähigkeit | Auswirkungen |
|---|---|---|
| CVSS-gesteuerte Überpriorisierung | SCA mit EPSS-Bewertung + Erreichbarkeit | Reduziert SCA Warteschlange um bis zu 80% |
| Fragmentierte Ergebnisse über verschiedene Tools hinweg | ASPM mit Cross-Layer-Korrelation | Bis zu 90 % Geräuschreduzierung |
| Kein geschäftlicher Kontext | Anlageninventar + Kritikalitätsanalyse | Ergebnisse geordnet nach tatsächlicher geschäftlicher Auswirkung |
| Kontextwechsel des Entwicklers | DevAI IDE-Integration | Korrekturen erfolgen zum Zeitpunkt der Erstellung, nicht zum Zeitpunkt der Ticketbearbeitung. |
| Manuelle Triage von Befunden mit niedrigem Risiko | Automatisierte Richtlinien + automatische Triage-Regeln | Ingenieure konzentrieren sich ausschließlich auf die EntwicklungcisIonen, die von Bedeutung sind |
| Falsch positive Ergebnisse von SAST | AI-powered SAST mit einer Falsch-Positiv-Rate von 16.7 % | Branchenführende SignalvorstufecisIon |
Xygenis SAST wurde mit dem verglichen OWASP-Benchmark und erreichte eine Trefferquote von 100 % in allen wichtigen Schwachstellenkategorien bei einer Fehlalarmrate von 16.7 %. Weniger Fehlalarme an der Quelle bedeuten weniger Störungen im gesamten System. pipeline.
Fazit
Alarmmüdigkeit ist kein Zeichen für das Versagen Ihres Teams. Sie ist vielmehr ein Zeichen dafür, dass Ihre Tools mehr Rauschen als Signal erzeugen – ein Problem, das sich lösen lässt.
Die Teams, die sich daraus befreien, erreichen dies nicht durch eine verschärfte Priorisierung. Sie erreichen es, indem sie ihr Priorisierungsmodell verbessern: durch die Hinzunahme von EPSS und Erreichbarkeit. SCAZusammenführung der Ergebnisse durch ASPM, indem Kontext in jede Benachrichtigung eingebettet und Feedback frühzeitig eingeleitet wird, damit Entwickler Probleme beheben können, bevor sie sich zu Rückständen anhäufen.
Das Ziel sind nicht weniger Warnmeldungen. Es ist eine Warteschlange, in der jede verbleibende Warnmeldung ein reales Risiko darstellt, das eine menschliche Überprüfung rechtfertigt.cisIon.
👉 Starten Sie Ihre kostenlose Testphase und konzentrieren Sie sich nur auf die Risiken, die wirklich wichtig sind.Scanergebnisse in wenigen Minuten, keine Kreditkarte erforderlich.
👉 Kontakt und sehen, wie ASPM Passt zu Ihrem spezifischen Tool-Stack und Ihrer Teamstruktur.

Über den Autor
Mitbegründer & CTO
Fatima Said spezialisiert sich auf entwicklerorientierte Inhalte für AppSec, DevSecOps und software supply chain securitySie wandelt komplexe Sicherheitssignale in klare, umsetzbare Anweisungen um, die Teams dabei helfen, schneller Prioritäten zu setzen, Störungen zu reduzieren und sichereren Code zu liefern.