MCP 安全性 现在,对于使用大型语言模型的DevSecOps团队来说,这已成为首要任务。 模型上下文协议(MCP) 允许LLM直接连接到开发者工具、本地环境,以及 CI/CD 系统实现了强大的自动化,但也带来了新的风险。随着这种联系的加深,通过实施强有力的控制措施至关重要。 MCP 服务器安全最佳实践 变得至关重要。如果没有适当的安全措施,人工智能助手可能会泄露机密信息、执行不安全的命令,或者无意中更改生产依赖项。
本文解释了模型上下文协议 (MCP) 的工作原理、它引入的漏洞以及如何有效地保护 MCP 服务器。此外,本文还展示了 Xygeni 如何帮助 DevSecOps 团队检测不安全因素。 人工智能与工具的交互 执行 guardrails并确保自动化在开发生命周期的每个阶段都安全可靠。
什么是模型上下文协议(MCP)?
什么是模型上下文协议(MCP)?
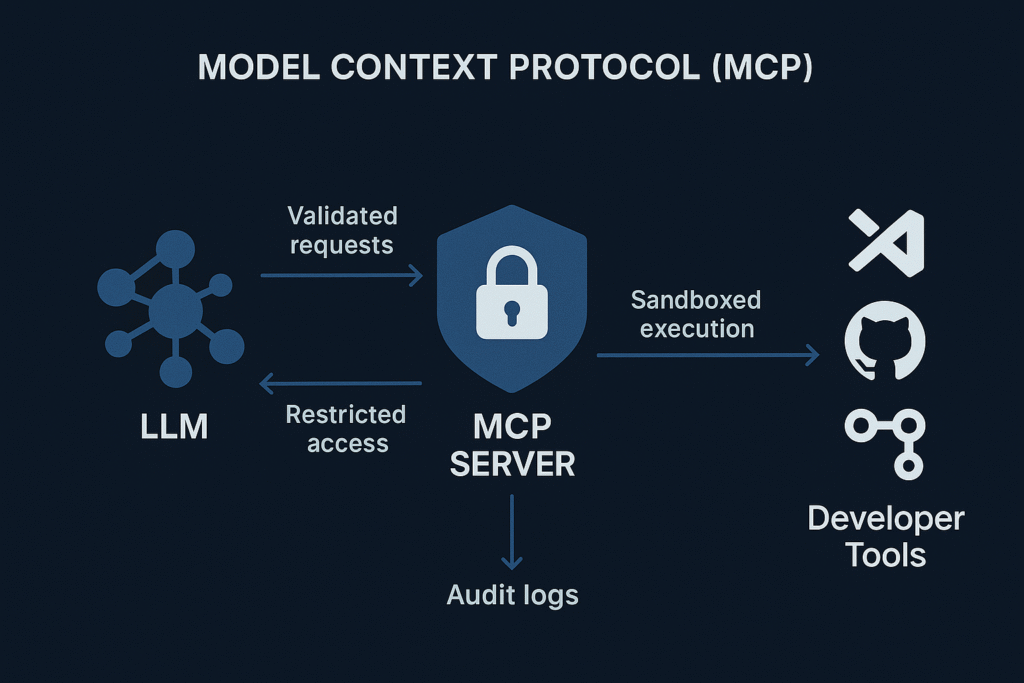
此 模型上下文协议 它定义了 LLM 与外部开发工具之间的通信层。现在,模型不再仅仅响应文本,而是可以向连接的系统发送结构化请求。例如,它可以调用 API、打开文件或从构建过程中检索日志。 pipeline.
实际上,MCP 使 LLM 能够成为开发环境中的“主动”助手。当开发人员要求模型运行测试、检查依赖项或扫描容器时,LLM 会通过 MCP 接口发送该请求。 MCP 服务器 接收到任务后,使用授权的本地工具执行任务。
这种交互方式节省了时间并减少了上下文切换。然而,它也使模型暴露于敏感资源,例如本地文件路径、凭据和系统命令。因此, MCP 安全性 必须确保人工智能能够在不越过预设边界的情况下安全交互。
MCP 服务器在 LLM-DevOps 集成中的工作原理
在典型的设置中, MCP 服务器 它充当LLM和开发者环境之间的安全桥梁。它解析模型请求,验证它们,并将它们转发给可信工具,例如: VS代码, GitHub动作,或 测试框架.
每个请求都包含上下文信息,例如模型想要访问的内容以及访问原因。然后服务器会决定是否允许该操作。理想情况下, MCP 安全性 该层会验证此上下文以避免不必要的操作。
例如:
- 当模型请求打开本地文件时,MCP 服务器会检查路径权限。
- 如果服务器想要安装某个软件包,它会验证软件包的来源和版本。
- 当命令涉及生产分支时,服务器可以要求人工批准。
这些检查构成了MCP服务器安全最佳实践的基础。 guardrails 防止模型执行超出其安全区域的操作。
MCP 安全的关键风险
虽然 模型上下文协议 虽然自动化程度有所提高,但也引入了多个攻击面。以下是需要密切关注的最相关风险:
- 1. 局部暴露: 如果 MCP 服务器缺乏隔离,LLM 可能会无意中访问本地文件、环境变量或敏感数据。这是 MCP 最常见的安全漏洞之一。
- 2. 秘密泄露: 不安全的配置可能会通过提示或响应暴露令牌、API密钥或凭据。这些泄露的信息会迅速通过日志或模型内存传播。
- 3. 命令注入: 由于LLM模型会生成文本,精心设计的提示可能会诱使模型发送有害命令。如果没有验证, MCP 服务器 可能会执行。
- 4. 依赖性篡改: 某些 MCP 配置允许 AI 自动安装或更新依赖项。如果未经验证,恶意软件包可能会危害本地环境。
- 5. 权限过高: 授予人工智能完整的系统权限可能导致不受控制的执行或横向移动。限制权限是 MCP 服务器安全最佳实践的核心之一。
这些风险都表明,模型上下文协议必须被视为组织安全边界的一部分。保护 API 或云工作负载的原则同样适用于 AI 与 DevOps 的集成。
MCP 服务器安全最佳实践
为了构建安全可靠的 MCP 集成,团队应采用分层保护策略。以下 MCP 服务器安全最佳实践有助于预防大多数常见安全事件:
| MCP 服务器安全最佳实践 | 描述 |
|---|---|
| 验证并清理所有请求 | 切勿直接执行模型请求。每次调用都必须经过验证规则,检查语法、意图和目标范围。 |
| 限制文件系统和网络访问 | 将模型的可见范围限制在特定目录或端点。隔离可以防止数据泄露并限制横向访问。 |
| 应用权限控制 | 明确模型可以使用的工具、API 和代码库。细粒度的访问控制能够确保 AI 活动的可预测性和安全性。 |
| 使用容器化或沙盒技术 | 每个 MCP 会话都在隔离环境中运行。这可以防止不同版本或用户之间交叉感染,并最大限度地减少潜在影响。 |
| 监测和审计活动 | 详细记录模型的每一次操作、命令和响应。监控有助于及早发现事件并进行合规性验证。 |
| 轮换令牌和分离凭证 | 将模型凭证与开发密钥分开存储。频繁轮换令牌可以降低重复使用或未经授权访问的风险。 |
当这些 MCP 服务器安全最佳实践共同实施时,可以构建强大的安全防护体系。 guardrails 这使得团队能够从模型上下文协议自动化中受益,而无需暴露核心系统。
Xygeni 对 MCP 安全性的看法
At 西吉尼安全团队看到了 模型上下文协议 既是一项突破,也是一个新领域 DevSecOps。 能够加快代码审查速度的人工智能,如果不加以控制,也可能扩大攻击面。
Xygeni 通过分析 LLM 如何与其发展互动,帮助组织管理这种新风险。 pipeline该平台能够检测不安全模式,例如通过 AI 提示或模型命令共享的、到达受保护环境的秘密信息。它还适用于 guardrails 阻止不安全操作,限制未经授权的命令,并在 MCP 连接中强制执行最小权限原则。
通过持续监测和情境分析,Xygeni 能够清晰地展现每个方面。 AI与DevOps的交互这使得团队更容易信任他们的人工智能工具,并确保自动化得以实现。 安全进入 pipeline而不是在它之外。
MCP 安全的未来
开发者工具中 LLM 的普及速度只会加快。不久之后,大多数 IDE、构建系统和代码仓库都将默认支持模型上下文协议。这种转变将大幅提升开发效率,但也给安全团队带来了新的责任。
随着越来越多的AI系统直接连接到源代码和基础设施,MCP安全性必须成为其中的一部分。 standard DevSecOps 工作流程。开发人员需要了解其 AI 助手的运行状况,确保策略得到有效执行,并持续获得保障,以保证其行为始终在安全范围内。
如今率先采用 MCP 服务器安全最佳实践的组织将引领这一安全转型。他们将在不牺牲控制权或信任的前提下,充分利用人工智能的速度优势。
总结
模型上下文协议将大型语言模型转变为软件开发的积极参与者。它将人工智能直接连接到开发人员日常使用的工具。然而,每一次新的连接都会扩大攻击面。
通过应用严格的 MCP 安全控制并遵循经过验证的 MCP 服务器安全最佳实践,团队可以在保持完全控制的同时,释放 AI 驱动自动化的优势。
Xygeni 帮助企业实现这种平衡。其平台可与现代系统无缝集成。 CI/CD 用于检测有风险的 AI-DevOps 流程、执行策略并确保每个 AI 操作都从设计上安全进行的环境。
开启免费体验! 使用 Xygeni 保护您的 AI-DevOps 集成